Introduction
As digital transformation accelerates, the explosive growth of data has become a defining characteristic of our era. It is estimated that 90% of the world’s data has been generated in just the past two years, and this trend continues at an unprecedented pace. Data now underpins enterprise decision-making, fuels AI-driven innovations, and redefines the modern technology stack. Often hailed as the “new oil,” data has evolved into a critical resource that can make or break an organization’s competitive edge.
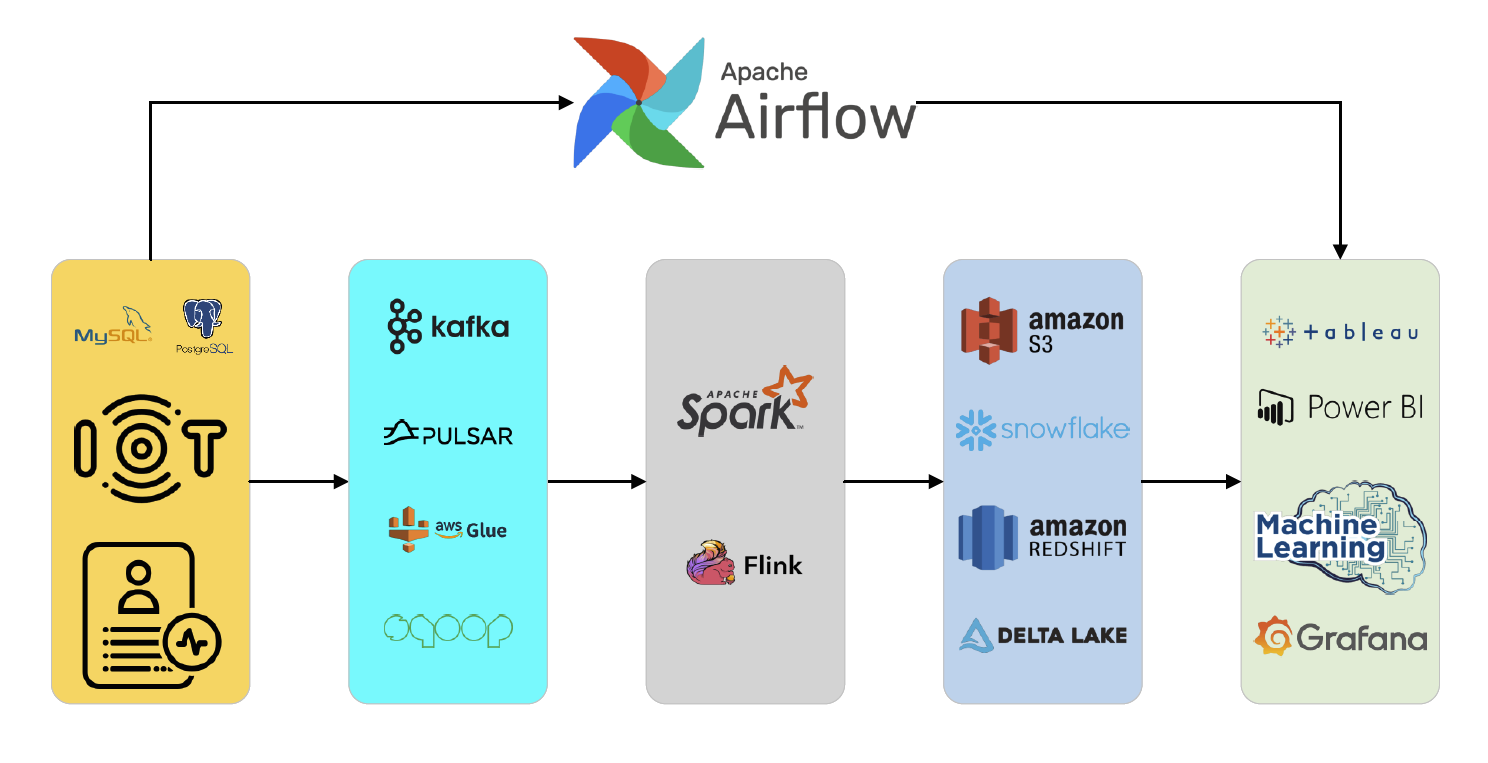
Yet building and operating a robust data pipeline to handle massive, fast-changing datasets is far from trivial. The complexity arises at every stage—from data collection to data consumption—and involves an ecosystem of tools and technologies that must work together seamlessly. In this blog, we will provide an end-to-end view of modern data architectures, focusing on five core stages (while also discussing orchestration and governance in detail): Data Collection, Data Ingestion, Data Processing, Data Storage, and Data Consumption. We will illustrate how enterprises can unify batch and stream processing, adopt lakehouse architectures, and enable advanced analytics, AI, and real-time monitoring.
1. Data Collection: Unifying Heterogeneous Sources
 Modern enterprises deal with diverse data sources of varying formats, velocities, and structures—each fulfilling a critical role in the business.
Modern enterprises deal with diverse data sources of varying formats, velocities, and structures—each fulfilling a critical role in the business.
1.1 Traditional Relational Databases
Transactional relational databases such as MySQL and PostgreSQL remain central to many operational systems, from e-commerce transactions to financial accounting. While these databases provide highly structured data, they also serve as valuable input for large-scale analytics tasks. Capturing changes from these databases in real-time, however, demands specialized tools to handle incremental updates and ensure minimal latency.
1.2 IoT and Sensor Data
With the rise of the Internet of Things (IoT), devices like smart home appliances and connected cars generate continuous streams of sensor data. These data points—often high-velocity and high-volume—necessitate efficient streaming solutions capable of handling near-real-time ingestion. Sensors might track everything from temperature readings to location data, enabling use cases such as predictive maintenance and fleet optimization.
1.3 User Behavior Logs
Modern web and mobile applications constantly produce user interaction and behavior logs, including clicks, page views, and in-app events. These logs are critical for understanding user engagement patterns, conducting A/B testing, and personalizing user experiences. They are usually semi-structured (e.g., JSON) or unstructured (e.g., raw text logs).
1.4 Unified Data Access Layer
To mask the complexity of multiple underlying data sources, enterprises often build a unified data access layer. Tools like Apache Flink or Apache NiFi can orchestrate data flows between disparate systems, simplifying ingestion and transmission. Meanwhile, Debezium specializes in Change Data Capture (CDC) for relational databases, streaming real-time insert, update, and delete events to downstream consumers. This approach ensures that as the source data evolves, those changes are immediately reflected in the data pipeline.
2. Data Ingestion: Moving from Sources to the Pipeline
 After gathering raw data, the next step is data ingestion—pulling data into the pipeline for further transformation and analysis.
After gathering raw data, the next step is data ingestion—pulling data into the pipeline for further transformation and analysis.
2.1 Real-Time (Streaming) Ingestion
For use cases that require low latency and rapid event processing, Apache Kafka and Apache Pulsar are popular choices. These high-throughput, fault-tolerant messaging systems excel in scenarios like fraud detection, IoT monitoring, or personalized recommendations.
- Example: An e-commerce platform streams user activity logs in real time to Kafka, where a downstream recommendation engine (built on Apache Flink) consumes these logs to provide instantaneous product suggestions.
2.2 Batch Ingestion
Large-scale historical data analysis often relies on batch ingestion strategies. Tools like Sqoop (commonly used to transfer bulk data between Hadoop and relational databases) or AWS Glue (for ETL tasks) handle periodic data transfers efficiently.
- Example: A retail company might run a nightly job that extracts sales transaction data from MySQL, loads it into Amazon S3 or HDFS, and subsequently triggers a Spark job for aggregated sales analysis.
2.3 Direct Computation
In some latency-sensitive scenarios, data may be directly ingested into a computation layer without being stored in a messaging system. This approach is less common in large-scale pipelines but can be optimal for microservices requiring immediate data processing. It also saves storage resources and reduces end-to-end latency.
3. Data Processing: The Fusion of Batch and Stream
 Data processing sits at the heart of any data pipeline, where raw data is transformed into actionable insights. Broadly, it falls into two categories: batch processing and stream processing.
Data processing sits at the heart of any data pipeline, where raw data is transformed into actionable insights. Broadly, it falls into two categories: batch processing and stream processing.
3.1 Batch Processing
Batch processing deals with large volumes of data in discrete intervals (e.g., daily, weekly, monthly). It is well-suited for recurring analytics tasks such as daily sales reports or monthly financial reconciliations.
- Apache Spark is a quintessential batch processing framework, offering in-memory computation and a rich ecosystem (DataFrame API, SparkSQL, MLlib) for machine learning at scale. With its distributed architecture, Spark can handle massive datasets with ease, providing robust fault tolerance and advanced analytics capabilities.
3.2 Stream Processing
Stream processing frameworks like Apache Flink or Apache Spark Structured Streaming focus on continuous, real-time data flows. As soon as an event arrives, it is processed, enabling use cases that require instant feedback or real-time analytics, such as anomaly detection or real-time user personalization.
- Example: A logistics company uses Apache Flink to process IoT sensor data from its fleet in real time, monitoring vehicle performance and predicting maintenance needs before failures occur.
3.3 Unified Batch-Stream Architectures
Modern frameworks are increasingly merging batch and stream processing, reducing the complexity of maintaining separate systems. Spark’s structured streaming capabilities, for instance, let developers write a single codebase that handles both historical data (batch) and incoming data (stream). This convergence streamlines development, cuts down operational overhead, and improves system maintainability.
4. Data Storage: Layered Approaches and Lakehouse Integration
 Once data is processed, it must be stored for future analysis, querying, and consumption. Organizations commonly adopt a layered approach that includes both data lakes and data warehouses, with a growing trend toward Lakehouse solutions.
Once data is processed, it must be stored for future analysis, querying, and consumption. Organizations commonly adopt a layered approach that includes both data lakes and data warehouses, with a growing trend toward Lakehouse solutions.
4.1 Data Lakes
A data lake is designed to store raw, unprocessed data in its original format. Solutions like Hadoop HDFS (on-premises) or Amazon S3 (in the cloud) provide scalable, cost-effective storage for disparate data types.
- Benefit: Storing all data in its native form maintains flexibility. Data scientists can revisit historical datasets for new machine learning or deep analytical needs, even if those use cases weren’t envisioned at the time of ingestion.
4.2 Data Warehouses
For fast, analytical querying over structured data, data warehouses are ideal. Platforms like Snowflake, Google BigQuery, or Amazon Redshift optimize for complex SQL queries, concurrency, and performance.
- Use Case: Marketing analysts can perform ad-hoc queries on user engagement metrics, slicing and dicing multi-dimensional data without significant latency.
4.3 Lakehouse
The concept of Lakehouse architecture combines the flexibility of a data lake with the performance characteristics of a data warehouse. Tools such as Databricks Delta Lake, Apache Iceberg, or Apache Hudi offer ACID transactions, schema enforcement, and time-travel capabilities on data stored in a lake-like environment. This design simplifies data management by consolidating raw data, structured data, and real-time updates under one unified architecture, supporting both batch and streaming workloads.
5. Data Consumption: Multi-Faceted Data-Driven Applications
 Ultimately, data has to be consumed by end-users or downstream systems to deliver tangible business value. Data consumption spans multiple domains, including Business Intelligence (BI), Artificial Intelligence (AI), and Real-Time Monitoring.
Ultimately, data has to be consumed by end-users or downstream systems to deliver tangible business value. Data consumption spans multiple domains, including Business Intelligence (BI), Artificial Intelligence (AI), and Real-Time Monitoring.
5.1 Business Intelligence
BI tools such as Tableau, Power BI, or Looker transform processed data into interactive dashboards and visualizations. This empowers stakeholders to make data-driven decisions, track key performance indicators (KPIs), and quickly respond to market changes.
- Example: An executive dashboard that visualizes real-time revenue, user growth, and product performance, aiding strategic decision-making across an enterprise.
5.2 Artificial Intelligence and Machine Learning
High-quality, clean, and enriched datasets are the foundation for training AI models—from recommendation engines to large language models (LLMs).
- Example: An online retail platform might combine user purchase histories and clickstream data to train a personalized recommendation algorithm using TensorFlow or PyTorch, boosting both user satisfaction and revenue.
5.3 Real-Time Monitoring
Tools like Grafana and Prometheus integrate with streaming data pipelines to provide real-time dashboards and alerts. In high-sensitivity industries like finance or security, second-level updates can be critical for detecting fraudulent transactions or potential breaches.
6. Orchestration and Governance: Ensuring System Stability and Data Quality
 As data pipelines grow increasingly complex, ensuring that each component runs efficiently, and that data remains trustworthy becomes paramount.
As data pipelines grow increasingly complex, ensuring that each component runs efficiently, and that data remains trustworthy becomes paramount.
6.1 Task Orchestration
Orchestration tools such as Apache Airflow, Dagster, or Luigi enable engineers to define complex workflows via Directed Acyclic Graphs (DAGs). These workflows manage dependencies, retries, event-based triggers, and scheduled runs, ensuring a seamless flow from raw data ingestion to final analytics.
- Example: A DAG could kick off a nightly Spark job for batch processing, then load the results into a data warehouse. If any step fails, Airflow automatically retries and notifies the operations team.
6.2 Data Governance
Data governance ensures that data quality, security, and compliance standards are met across the organization. Modern governance frameworks often include a data catalog and data quality monitoring components.
- Metadata Management and Cataloging: Tools like DataHub or Amundsen build comprehensive data catalogs, making datasets easily discoverable and understandable.
- Data Quality and Consistency: Automated checks can validate schemas, enforce rules, and trigger alerts if data deviates from expected patterns.
- Access Control: Ensuring compliance (e.g., GDPR, CCPA) often requires role-based permissions, data masking, and auditing to track how data is accessed and modified.
Conclusion
Modern data architectures increasingly rely on open-source tools and flexible, composable frameworks to construct end-to-end pipelines that address the challenges of massive data volume, velocity, and variety. By combining batch and stream processing, data lakes and data warehouses, and robust governance practices, organizations can keep pace with growing business demands and unlock valuable AI-driven innovations.
From building a unified data access layer for myriad data sources, to orchestrating large-scale processing in Apache Spark or Flink, to adopting Lakehouse solutions like Databricks Delta Lake or Apache Iceberg, each layer of the pipeline contributes to a holistic solution. The ability to quickly ingest, transform, store, and analyze data is now a critical differentiator for enterprises striving to thrive in the data-driven era.
By mastering these core technologies, businesses can optimize operations, deliver real-time insights, and power the next wave of AI-driven products and services—ultimately standing out in a world where data truly is the new oil.