1. Introduction
Data Engineering has emerged as a pivotal discipline in today’s data-driven landscape. Organizations rely on Data Engineers to design pipelines, ensure data quality, and optimize cloud infrastructure. To uncover the most sought-after skills, tools, and qualifications for Data Engineering roles in the UK, we conducted a text mining project on job descriptions scraped from LinkedIn. This report outlines the methodology—from data cleaning through advanced analytics methods—and highlights insights derived from clustering and Social Network Analysis (SNA). Equipped with these findings, job seekers can better tailor their skill sets, and hiring managers can gain clarity on the evolving demands of the market.
2. Methodology
Our text mining pipeline consisted of four primary stages:
2.1 Data Cleaning
- Dataset Collection
- We initially scraped 1,000 Data Engineering job postings from LinkedIn on 14th December 2024, specifically targeting roles based in the UK.
- After removing duplicates, incomplete listings, and near-identical entries, we consolidated the dataset to 644 unique records.
- Text Pruning
- Non-relevant information—such as company intros, office locations, and benefits—was excised to isolate skill requirements.
- We removed recruitment-domain “stopwords” (e.g., “benefits,” “remote,” “company”) in addition to standard English stopwords.
- Normalization
- Lemmatization unified variations of words (e.g., “engineers” → “engineer”).
- Whitespace, punctuation, and special characters were standardized. Segmentation errors such as “DataEngineer” were corrected to “Data Engineer.”
- Deduplication
- Any repeated or near-duplicate postings were identified and removed, culminating in a high-quality, domain-specific corpus of 644 entries.
2.2 Keyword Extraction
We employed KeyBERT—powered by the distilbert-base-uncased model—to extract 5 keywords and short phrases from each job description. Maximum Marginal Relevance (MMR) ensured a balance between keyword relevance and diversity. Formally:
\[ \text{MMR} = \arg \max_{\mathbf{D}_i \in \mathbf{R} \setminus \mathbf{S}} \left[ \lambda \text{Sim}(\mathbf{D}_i, \mathbf{Q}) - (1 - \lambda) \max_{\mathbf{D}_j \in \mathbf{S}} \text{Sim}(\mathbf{D}_i, \mathbf{D}_j) \right] \]
where Sim is typically cosine similarity, R is the set of candidate phrases, S is the set of already chosen phrases, and Q is the document.
2.3 Semantic Clustering
After extracting keywords, we generated semantic embeddings using SentenceTransformer (all-MiniLM-L6-v2). These embeddings capture the contextual meaning of each keyword. We then performed Hierarchical Clustering with Ward’s linkage and cosine similarity as the distance metric:
- Cosine Similarity
\[ \text{Sim}(\mathbf{A}, \mathbf{B}) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} \]
Cosine similarity effectively measures the angular distance between embedding vectors and is particularly robust for text-based tasks.
- Ward's Linkage
Ward's method aims to minimize the total within-cluster variance:
\[ D_{ij} = \frac{n_i n_j}{n_i + n_j} || c_i - c_j ||^2 \]
2.4 Social Network Analysis (SNA)
For the SNA, we treated each keyword as a node, linking them by edges representing co-occurrences within the same job descriptions:
- Network Construction
- We built a co-occurrence matrix M where Mij counts how often keywords i and j appear together.
- Low-frequency connections were filtered out to eliminate noise.
- Undirected, Weighted Graph
- Our resulting graph is undirected, with edge weights corresponding to co-occurrence frequency.
- Node size in Gephi often correlates with the node’s degree or weighted degree.
- Network Metrics
- Degree Centrality: Indicates how many connections a node has.
- Betweenness Centrality: Shows the extent to which a node serves as a “bridge” within the network.
- Clustering Coefficient: Reflects how interconnected a node’s neighbors are.
3. Results
3.1 Keyword Overview

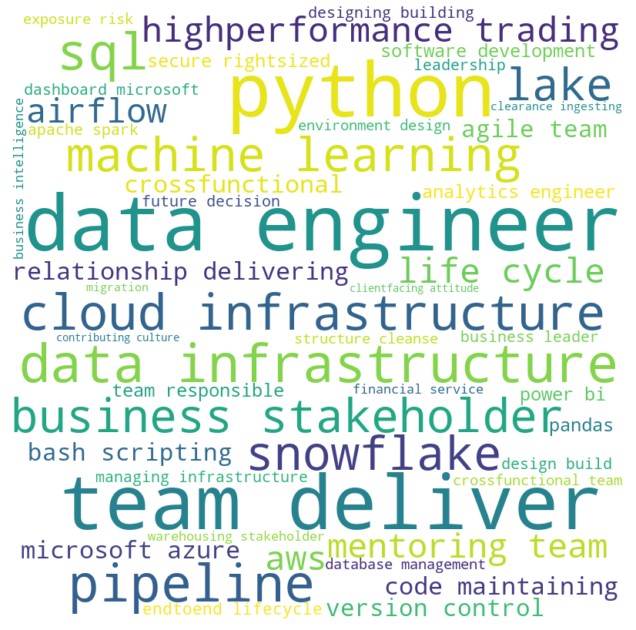
In addition to generating a word cloud, we tallied the frequency of each keyword across the 644 cleaned job descriptions (see partial data below). This helps contextualize which skills and terms appear most prominently in the dataset:

From this table, “data engineer” (200 occurrences) stands out as the most frequently mentioned term, reflecting its central role in the job descriptions. “team deliver” (165) appears surprisingly high, emphasizing the collaborative environment that Data Engineers operate in. “python” (151) reaffirms the predominance of programming expertise, while “data infrastructure” (115), “pipeline” (88), and “sql” (78) underscore the criticality of building and maintaining robust data pipelines.
Overall, these frequency counts align with the semantic clusters and SNA results, showing that both technical and collaborative dimensions of Data Engineering remain top priorities for employers.
3.2 Clustering Outcomes

Through hierarchical clustering, the keywords with occurrences over 15 formed six principal clusters, as summarized below:
- Team Collaboration
- Examples: “team deliver,” “agile team,” “mentoring team,” “team responsible.”
- Focus: Collaboration, leadership, and active team roles.
- Data Pipeline Tools
- Examples: “pipeline,” “snowflake,” “power bi,” “lake,” “airflow,” “life cycle.”
- Focus: Orchestration platforms, BI reporting, and data-lake architectures.
- Stakeholder Engagement
- Examples: “nontechnical stakeholder,” “relationship delivering,” “secure rightsized,” “crossfunctional,” “highperformance trading.”
- Focus: Communicating with diverse stakeholders, ensuring security, and specialized domains (e.g., trading).
- Cloud Infrastructure
- Examples: “data infrastructure,” “cloud infrastructure,” “aws,” “microsoft azure.”
- Focus: Emphasis on deploying and maintaining scalable cloud-based solutions.
- Engineering & Software Development
- Examples: “data engineer,” “analytics engineer,” “software development.”
- Focus: Bridging advanced engineering practices and data-centric roles.
- Core Technical Skills
- Examples: “python,” “machine learning,” “version control,” “sql,” “code maintaining,” “pandas,” “bash scripting.”
- Focus: Programming, ML integration, DevOps fundamentals, and scripting languages.
3.3 Expanded Social Network Analysis

For our SNA in Gephi, each keyword is a node linked by co-occurrences in the same job description:
- High-Degree Nodes
- Python and SQL consistently appear in tandem with diverse tools and concepts, reflecting their foundational role in data workflows.
- AWS also ranks high in node connections, highlighting the prevalent use of Amazon’s cloud services.
- Bridging Keywords
- Python demonstrates notable betweenness centrality, linking machine learning tasks with code maintenance and version control.
- Data infrastructure forms a bridge between pipeline tools (Snowflake, Airflow) and multi-cloud requirements (AWS, Azure).
- Community Pockets
- A sub-community of ML-oriented keywords (e.g., “machine learning,” “pandas,” “analytics engineer”) co-occurs frequently, signaling the integration of ML tasks within Data Engineering pipelines.
- Another cluster combines cloud infrastructure with pipeline tools, revealing a strong synergy between scaling architectures and orchestrating data flows.
- Soft-Skill Intersection
- “team deliver,” “mentoring team,” and “crossfunctional” connect to both technical keywords (pipeline, Python) and stakeholder-oriented terms, highlighting the interplay of communication and coding expertise.
Overall, the SNA reveals how frequently mentioned skills (e.g., Python, SQL) act as hubs, while related keywords (e.g., “airflow,” “machine learning”) form specialized clusters that branch out from these core competencies.
4. Insights
- Python and SQL as Cornerstone Skills
- The frequency table, clustering, and SNA collectively indicate that Python and SQL dominate job requirements, serving as the backbone for data manipulation and pipeline tasks.
- Evolving Cloud Demand
- High frequencies for “cloud infrastructure” (59), “aws” (25), and “microsoft azure” (18) confirm the push toward multi-cloud expertise.
- Cloud solutions tightly integrate with pipeline tools such as Snowflake and Airflow.
- Collaboration & Stakeholder Focus
- Unexpectedly high frequencies for “team deliver” (165), “relationship delivering” (20), and “crossfunctional” (19) illustrate the necessity for strong communication and collaborative abilities in Data Engineering.
- Machine Learning On the Rise
- The presence of “machine learning” (41) alongside robust co-occurrences in SNA suggests a rising emphasis on operationalizing ML models within Data Engineering pipelines.
5. Conclusion
In this text mining project, we integrated hierarchical clustering and Social Network Analysis to uncover the trends shaping Data Engineering roles in the UK. The keyword frequency table highlights the preeminence of “data engineer,” “team deliver,” and “python,” underscoring the dual requirement of technical prowess and collaborative capabilities. Hierarchical clustering groups these keywords into thematic clusters, while the SNA visualization shows how skills and tools co-occur and form network communities in practical contexts.
Overall, the findings confirm that Data Engineering demands strong coding fundamentals (Python, SQL), orchestration/pipeline expertise (Airflow, Snowflake), cloud proficiency (AWS, Azure), and cross-team collaboration. As the data domain continues to evolve—integrating machine learning and advanced analytics—professionals who balance these capabilities are well-positioned to meet industry needs, and employers can optimize their hiring strategies by focusing on these core skill sets.