Many financial analysts and data engineers require large volumes of historical stock data for backtesting, risk models, or real-time analytics. Traditionally, collecting 10+ years of data for hundreds of tickers could take hours. By harnessing asynchronous I/O in Python (asyncio + asyncio.to_thread), combined with yfinance for data retrieval and PostgreSQL for robust storage, the same job can finish in mere seconds or under a minute, even for over one million rows of data.
1. Setting Up the PostgreSQL Database
Before we dive into the Python code, let’s ensure we have a PostgreSQL database ready. You can create it via the psql terminal (or a GUI like pgAdmin). Below is an example of how to create a database and a user:
-- Connect to PostgreSQL as a superuser (e.g., "postgres")
psql -U postgres
-- Create a new database
CREATE DATABASE finance_db;
-- Optionally, create a dedicated user
CREATE USER finance_user WITH PASSWORD 'securepassword';
-- Grant privileges to the new user
GRANT ALL PRIVILEGES ON DATABASE finance_db TO finance_user;
-- Exit psql
\q
Now you have a finance_db database and a finance_user who can access it. This sets the stage for our data ingestion pipeline.
2. Extracting and Validating S&P 500 Tickers
2.1 Fetching Symbols from Wikipedia
The S&P 500 constituents can be scraped directly from Wikipedia using pandas.read_html. The snippet below retrieves the first table on the page and extracts the “Symbol” column:
import pandas as pd
def get_sp500_tickers():
url = "https://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
try:
sp500_table = pd.read_html(url)[0]
sp500_tickers = sp500_table["Symbol"].tolist()
return sp500_tickers
except Exception as e:
print(f"Error fetching S&P 500 data: {e}")
return []
sp500_tickers = get_sp500_tickers()
print(f"S&P 500 Ticker Count: {len(sp500_tickers)}")
print(sp500_tickers)

2.2 Fixing Ticker Symbols
Some symbols—like BRK.B—must be changed to BRK-B to match Yahoo Finance’s format:
def fix_invalid_tickers(tickers):
return [ticker.replace('.', '-') for ticker in tickers]
2.3 Asynchronous Validation
We validate each ticker asynchronously to confirm it returns data on Yahoo Finance:
import asyncio
import yfinance as yf
async def validate_ticker_async(ticker):
try:
stock = yf.Ticker(ticker)
data = await asyncio.to_thread(stock.history, period="1d")
return not data.empty
except Exception:
return False
async def validate_all_tickers_async(tickers, max_concurrent=50):
semaphore = asyncio.Semaphore(max_concurrent)
async def validate_with_semaphore(sym):
async with semaphore:
return sym, await validate_ticker_async(sym)
tasks = [validate_with_semaphore(t) for t in tickers]
results = await asyncio.gather(*tasks)
valid = [t for t, ok in results if ok]
invalid = [t for t, ok in results if not ok]
return valid, invalid
- asyncio.to_thread: Offloads the blocking .history() call to a background thread, leaving the main coroutine free to schedule other tasks.
- We also use a semaphore to limit concurrency (defaulting to 50 tasks at once).
3. Filtering for 10+ Years of Data
We next assess how many years of data each ticker provides on Yahoo Finance. Only those with at least 10 years of history will be fetched in bulk.
3.1 Collecting Date Ranges
async def get_stock_time_range(ticker):
try:
stock = yf.Ticker(ticker)
data = await asyncio.to_thread(stock.history, period="max")
if not data.empty:
start_date = data.index.min().strftime('%Y-%m-%d')
end_date = data.index.max().strftime('%Y-%m-%d')
return ticker, start_date, end_date
else:
return ticker, None, None
except Exception as e:
print(f"Error fetching {ticker}: {e}")
return ticker, None, None
async def get_all_stocks_time_ranges(tickers, max_concurrent=50):
semaphore = asyncio.Semaphore(max_concurrent)
async def fetch_with_semaphore(sym):
async with semaphore:
return await get_stock_time_range(sym)
tasks = [fetch_with_semaphore(t) for t in tickers]
return await asyncio.gather(*tasks)
3.2 Determining Which Tickers Qualify
We store the results in a DataFrame, then calculate each ticker’s total Years Available:
df['Start Date'] = pd.to_datetime(df['Start Date'])
df['End Date'] = pd.to_datetime(df['End Date'])
df['Years Available'] = (df['End Date'] - df['Start Date']).dt.days / 365.25
long_history_df = df[df['Years Available'] >= 10]
long_history_tickers = long_history_df['Ticker'].tolist()
print(f"Long History Ticker Count: {len(long_history_tickers)}")
print(f"Long History Tickers: {long_history_tickers}")

4. Setting Up PostgreSQL in Python
With the finance_db database created, we can connect using SQLAlchemy. You can adapt the credentials to your environment.
from sqlalchemy import create_engine, text
DATABASE = {
'drivername': 'postgresql',
'host': 'localhost',
'port': '5432',
'username': 'finance_user', # or 'postgres'
'password': 'securepassword', # the password you set
'database': 'finance_db',
}
engine = create_engine(
f"{DATABASE['drivername']}://{DATABASE['username']}:{DATABASE['password']}@"
f"{DATABASE['host']}:{DATABASE['port']}/{DATABASE['database']}"
)
with engine.connect() as connection:
print("Connected to PostgreSQL database successfully!")
4.1 Creating the Table
def create_table():
with engine.connect() as conn:
conn.execute(text("""
CREATE TABLE IF NOT EXISTS stock_daily_data (
Ticker VARCHAR(10),
Date DATE,
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Adj_Close FLOAT,
Volume BIGINT,
PRIMARY KEY (Ticker, Date)
);
"""))
print("Table created successfully!")
This schema holds ticker, date, OHLC prices, adjusted close, and volume, with a composite primary key on (Ticker, Date).
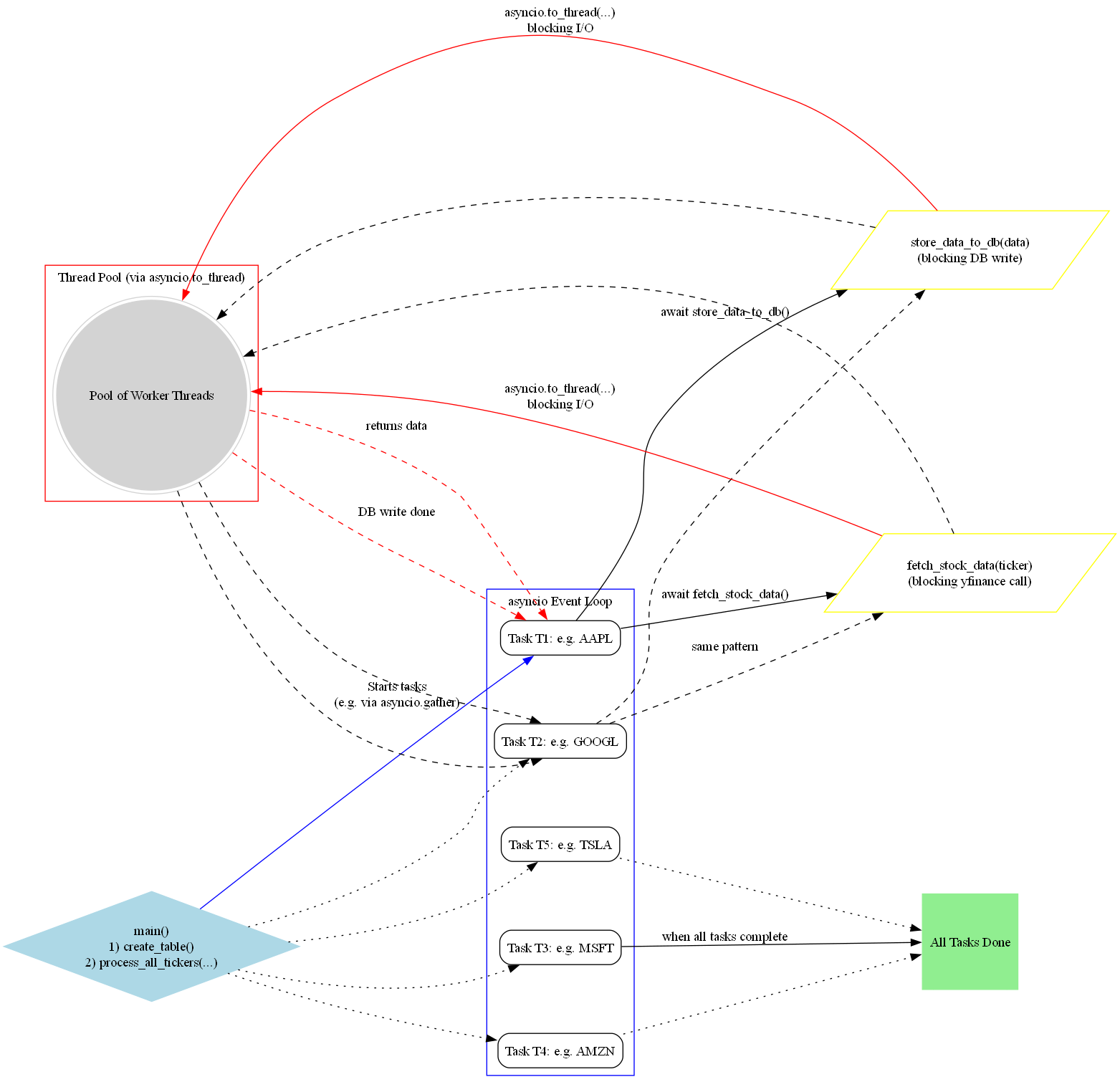
5. Asynchronous Data Retrieval and Persistence
5.1 Fetching the Daily Records
For each ticker, we perform an I/O-bound request to Yahoo Finance via yfinance. We offload the .history() call to a thread so our event loop can schedule multiple fetches simultaneously:
import datetime
import asyncio
async def fetch_stock_data(ticker, start_date, end_date):
try:
stock = yf.Ticker(ticker)
data = await asyncio.to_thread(
stock.history,
start=start_date,
end=end_date,
interval="1d"
)
data.reset_index(inplace=True)
data["Ticker"] = ticker
return data
except Exception as e:
print(f"Error fetching data for {ticker}: {e}")
return pd.DataFrame()
5.2 Writing to PostgreSQL
pandas.to_sql is typically a blocking operation, so we also run it in a thread:
async def store_data_to_db(data):
try:
await asyncio.to_thread(
data.to_sql,
"stock_daily_data",
con=engine,
if_exists="append",
index=False
)
print("Data inserted successfully!")
except Exception as e:
print(f"Error storing data: {e}")
5.3 Orchestrating All Tickers
We combine the fetching and storing steps into one task per ticker:
async def process_ticker(ticker, start_date, end_date):
print(f"Fetching data for {ticker}...")
data = await fetch_stock_data(ticker, start_date, end_date)
if not data.empty:
await store_data_to_db(data)
async def process_all_tickers(tickers, start_date, end_date, max_concurrent=50):
semaphore = asyncio.Semaphore(max_concurrent)
async def process_with_semaphore(sym):
async with semaphore:
await process_ticker(sym, start_date, end_date)
tasks = [process_with_semaphore(t) for t in tickers]
await asyncio.gather(*tasks)
By leveraging concurrency (max_concurrent=50), we effectively create 50 parallel I/O requests at any given moment, drastically cutting down the total runtime.
6. Bringing It All Together
Finally, here is a conceptual main() function that stitches everything together. We target 10 years of daily data by subtracting 10 * 365 days from today’s date:
import nest_asyncio
nest_asyncio.apply() # For Jupyter Notebook compatibility
async def main():
# 1. Create the table if it doesn't exist
create_table()
# 2. Set the desired 10-year window
start_date = (datetime.date.today() - datetime.timedelta(days=10 * 365)).strftime("%Y-%m-%d")
end_date = datetime.date.today().strftime("%Y-%m-%d")
# 3. Fetch and store data for tickers with >=10 years of history
await process_all_tickers(long_history_tickers, start_date, end_date)
# In Jupyter Notebook:
await main()


Conclusion
By integrating asyncio and yfinance with a robust PostgreSQL backend, you can rapidly ingest millions of data points from Yahoo Finance. The secret sauce lies in:
- Asynchronous I/O: Multiple .history() calls execute concurrently, minimizing idle time.
- Thread Offloading: Blocking operations—data fetches and database inserts—are dispatched to threads, keeping the main event loop unblocked.
- PostgreSQL: Provides a powerful, scalable store for subsequent queries, analysis, or modeling tasks.